|
I am a PhD student in Computer Science at York University, supervised by Dr. Kosta Derpanis in the CVIL Lab. My research focuses on mechanistic interpretability of video diffusion models, with a broader interest in 3D computer vision and generative modeling. Previously, I completed my M.Sc. at York University under Dr. Marcus Brubaker, where I worked on generative novel view synthesis and scale ambiguity. I interned at the Vector Institute and at VITA Lab in EPFL. Before my graduate studies, I completed my B.Sc. in Computer Engineering at Sharif University of Technology. |

|
|
|
|
|
|
|
|

|
Sharon S. Musa, Fereshteh Forghani, Harrish Thasarathan, Sonia Joseph, Matthew Kowal, Konstantinos Derpanis ICML 2026 Mech Interp workshop project page We probe spatiotemporal representations in video foundation models, investigating what, where, and how visual information is encoded across different architectures and training objectives. |

|
Fereshteh Forghani, Jason J. Yu, Tristan Aumentado-Armstrong, Konstantinos G. Derpanis, Marcus A. Brubaker, ArXiv 2025 (in submission) project page / arXiv
We propose a framework to estimate scene scales jointly with the GNVS model in an end-to-end fashion. We also define two new metrics, Sample Flow Variability (SFV) and Scale-Sensitive Thresholded Symmetric Epipolar Distance (SS-TSED),that directly measure the variability of scale learned by a GNVS method. |
|
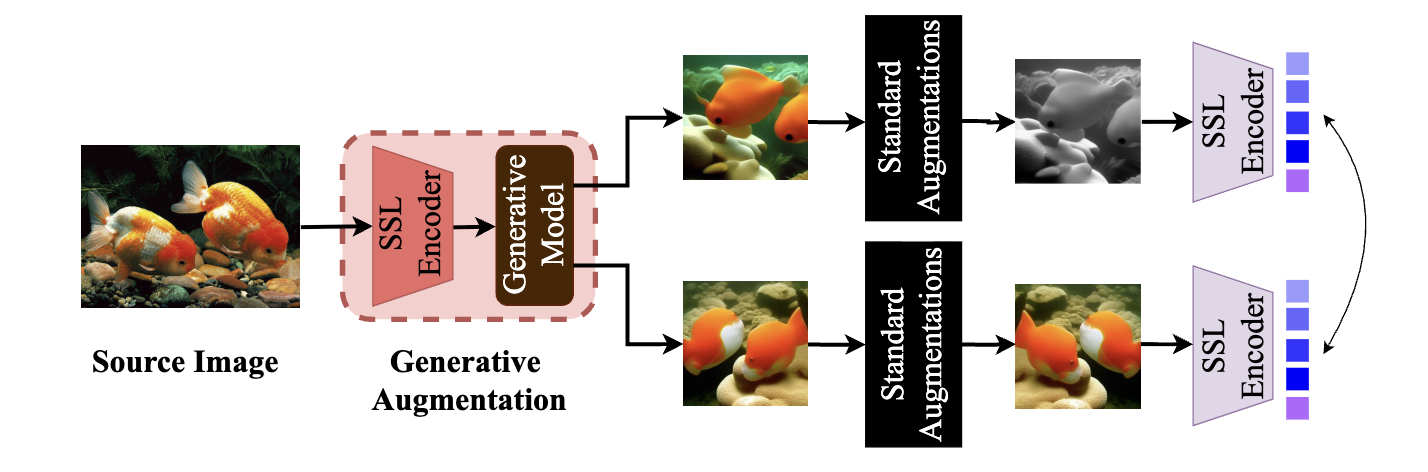
Sana Ayromlou, Vahid Reza Khazaie, Fereshteh Forghani, Arash Afkanpour, AAAI 2025 arXiv
we introduce a framework that enriches the self-supervised learning (SSL) paradigm by utilizing generative models to produce semantically consistent image augmentations. By directly conditioning generative models on a source image, our method enables the generation of diverse augmentations while maintaining the semantics of the source image, thus offering a richer set of data for SSL. |

|
Jason J. Yu, Tristan Aumentado-Armstrong, Fereshteh Forghani, Konstantinos G. Derpanis, Marcus A. Brubaker, ECCV 2024 project page / arXiv / code
we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of views. Our approach is not limited to generating a single image at a time and can condition on a variable number of views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. |

|
Jason J. Yu, Fereshteh Forghani, Konstantinos G. Derpanis, Marcus A. Brubaker, ICCV 2023 project page / arXiv / code
we propose a novel generative model capable of producing a sequence of photorealistic images consistent with a specified camera trajectory, and a single starting image. To measure the consistency over a sequence of generated views, we introduce a new metric, the thresholded symmetric epipolar distance (TSED), to measure the number of consistent frame pairs in a sequence. |
|
Design and source code from Jon Barron's website. |